~ cd 3.1. синтез в деталях
Синтез, как правило, можно разделить на coarse-grain, and fine-grain синтез. Мы видели это в Синтезатор, где конструкция была загружена и проработана, а затем прошла через серию coarse-grain оптимизаций, прежде чем был отображен на аппаратные(IP) блоки и fine-grain ячейки. Большинство команд в Yosys нацелены либо на coarse-grain, либо на fine-grain представление, и лишь некоторые из них совместимы с обоими состояниями.
Такие команды, как proc, fsm и memory, опираются на дополнительную информацию, содержащуюся в coarse-grain представлении, а также на ряд оптимизаций, таких как wreduce, share и alumacc. opt обеспечивает оптимизации, полезные в обоих состояниях, а techmap используется для преобразования coarse-grain ячеек в соответствующее fine-grain представление.
Однобитные ячейки (логические вентили, FFs), а также LUT, полусумматоры и полные сумматоры составляют основную часть fine-grain представления и необходимы для таких команд, как abc /abc9, simplemap, dfflegalize и memory_map .
3.1.1. Команды синтезатора
3.1.1.1. Пакетные команды synth_
Ниже приведен список всех команд синтезатора, включенных в Yosys для различных платформ. Каждая команда запускает скрипт, состоящий из подкоманд, специфичных для данной платформы. Обратите внимание, что не все эти скрипты активно поддерживаются и могут быть неактуальны.
- synth_achronix — синтез для ПЛИС Achronix Speedster22i.
- synth_anlogic — синтез для ПЛИС Anlogic
- synth_coolrunner2 — синтез для CPLD-матриц Xilinx Coolrunner-II
- synth_easic — синтез для платформы eASIC
- synth_ecp5 — синтез для ПЛИС ECP5
- synth_efinix — синтез для ПЛИС Efinix
- synth_fabulous — скрипт синтеза FABulous
- synth_gatemate — синтез для ПЛИС Cologne Chip GateMate
- synth_gowin — синтез для ПЛИС Gowin
- synth_greenpak4 — синтез для ПЛИС GreenPAK4
- synth_ice40 — синтез для ПЛИС iCE40
- synth_intel — синтез для ПЛИС Intel (Altera). (MAX10, Cyclone IV)
- synth_intel_alm — синтез для ПЛИС Intel (Altera) на базе ALM. (Cyclone V, Arria V, Cyclone 10 GX)
- synth_lattice — синтез для ПЛИС Lattice
- synth_nexus — синтез для ПЛИС Lattice Nexus
- synth_quicklogic — Синтез для ПЛИС QuickLogic
- synth_sf2 — синтез для ПЛИС SmartFusion2 и IGLOO2
- synth_xilinx — синтез для ПЛИС Xilinx
3.1.1.2. Общий синтез
В дополнение к перечисленным выше командам синтеза, специфичным для конкретного оборудования, существует также prep — общий скрипт синтеза. Эта команда ограничивается coarse-grain синтезом, не вдаваясь в какие-либо специфические для архитектуры сопоставления или оптимизации. Помимо прочего, она полезна для верификации конструкции.
Следующие команды выполняются командой prep:
begin:
hierarchy -check [-top <top> | -auto-top]
coarse:
proc [-ifx]
flatten (if -flatten)
future
opt_expr -keepdc
opt_clean
check
opt -noff -keepdc
wreduce -keepdc [-memx]
memory_dff (if -rdff)
memory_memx (if -memx)
opt_clean
memory_collect
opt -noff -keepdc -fast
check:
stat
checkСинтезатор рассказывает о большинстве этих команд и о том, что они делают.
3.1.2. Преобразование процедурных блоков
Фронтенде Verilog происходит преобразование блоков always в RTL нетлисты для выражений и «processess» для элементов управления и памяти. Затем команда proc преобразует эти «processess» в нетлисты RTL мультиплексоров и регистровых ячеек. Это также макрокоманда, которая вызывает другие команды proc_* в установленном порядке:
proc_clean # removes empty branches and processes
proc_rmdead # removes unreachable branches
proc_prune
proc_init # special handling of “initial” blocks
proc_arst # identifies modeling of async resets
proc_rom
proc_mux # converts decision trees to multiplexer networks
proc_dlatch
proc_dff # extracts registers from processes
proc_memwr
proc_clean # this should remove all the processes, provided all went fine
opt_expr -keepdcПосле всех команд proc_* вызывается opt_expr. Это можно отключить, вызвав proc -noopt.
Многие команды не могут работать с модулями, содержащими «processess». Обычно вызов proc является первой командой в процедуре синтеза после элаборации конструкции.
Пример
docs/source/code_examples/synth_flow.
module test(input D, C, R, output reg Q);
always @(posedge C, posedge R)
if (R)
Q <= 0;
else
Q <= D;
endmoduleЛистинг 3.3: proc_01.ys
read_verilog proc_01.v
hierarchy -check -top test
proc;;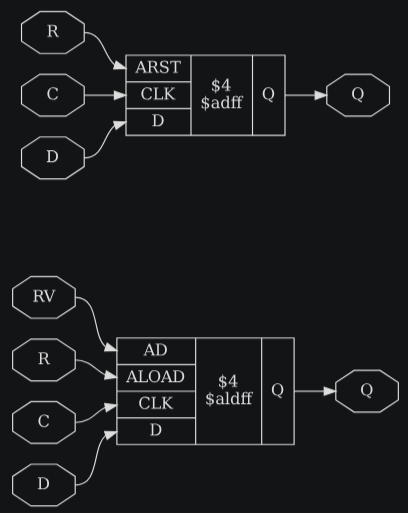
module test(input D, C, R, RV, output reg Q);
always @(posedge C, posedge R)
if (R)
Q <= RV;
else
Q <= D;
endmoduleЛистинг 3.5: proc_02.ys
read_verilog proc_02.v
hierarchy -check -top test
proc;;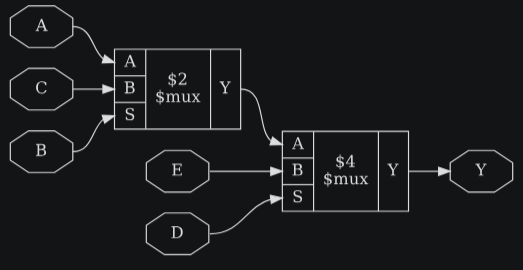
read_verilog proc_03.v
hierarchy -check -top test
proc;;module test(input A, B, C, D, E, output reg Y);
always @* begin
Y <= A;
if (B)
Y <= C;
if (D)
Y <= E;
end
endmodule3.1.3. Обработка FSM
Команда fsm определяет, извлекает, оптимизирует (перекодирует) и пересинтезирует конечные автоматы. Она представляет собой макрос, вызывающий ряд других команд:
# Нахождение и извлечение FSMs:
fsm_detect
fsm_extract
# Базовая оптимизация:
fsm_opt
opt_clean
fsm_opt
# Расширение на логику вентилей (если был вызов с параметром -expand):
fsm_expand
opt_clean
fsm_opt
# Перекодирование состояний FSM (если не было при вызове параметра -norecode):
fsm_recode
# Print information about FSMs:
fsm_info
# Экспортирование FSM в Формат файла KYSS2 (если был вызов с параметром -export):
fsm_export
# Отображения FSMs в RTL ячейках (если не было при вызове параметра -nomap):
fsm_mapАлгоритмы, используемые для обнаружения и извлечения FSM, находятся под влиянием более общей техники.
3.1.3.1. Обнаружение FSM
Команда fsm_detect идентифицирует регистры состояния FSM. Она устанавливает атрибут \fsm_encoding = «auto» для любого (многобитного) провода, который соответствует следующему описанию:
- Не имеет атрибута \fsm_encoding.
- Не является выходом модуля.
- Управляется одной ячейкой $dff или $adff.
- D-вход этой ячейки $dff или $adff управляется деревом мультиплексоров, на выходе которого находятся только константы или старое значение состояния.
- Значение состояния используется только в указанном дереве мультиплексоров или в простых реляционных ячейках, которые сравнивают значение состояния с константой (обычно это ячейки $eq).
Эта система хорошо себя зарекомендовала. Ее можно переписать, установив \fsm_encoding = «auto» для регистров, которые должны считаться регистрами состояния FSM, и установив \fsm_encoding = «none» для регистров, которые соответствуют вышеуказанным критериям, но не должны считаться регистрами состояния FSM.
Однако обратите внимание, что маркировка регистров состояний с \fsm_encoding, которые не подходят для перекодировки FSM, может привести к сбою синтеза или недостоверным результатам.
3.1.3.2. Извлечение FSM
Команда fsm_extract действует на все сигналы состояния, помеченные атрибутом (\fsm_encoding != «none»).
Для каждого сигнала состояния определяется следующая информация:
- регистры состояний
- Состояние асинхронного сброса, если регистры состояния используют асинхронный сброс
- Все состояния и входные сигналы управления, используемые в функциях перехода из одного состояния в другое
- Выходные сигналы управления, рассчитанные на основе сигналов состояния и управляющих входов
- Таблица всех переходов из одного состояния в другое и соответствующих управляющих входов и выходов
Регистры состояния (и сигналы асинхронного сброса, если применимо) просто определяются путем идентификации источника для сигнала состояния.
Отсюда рекурсивно обходится $mux-дерево, управляемое входами регистра состояний. Все входы селектора являются управляющими сигналами, а входы $mux-дерева — состояниями. Алгоритм терпит неудачу, если найден неконстантный вход, не являющийся сигналом состояния.
Список управляющих выходов инициализируется битами из сигнала состояния. Затем он расширяется путем добавления всех значений, которые вычисляются ячейками, сравнивающими сигнал состояния с постоянным значением.
В большинстве случаев это охватывает все случаи использования регистра состояния, что делает кодирование состояния произвольным. Однако если в проекте используется, например, один бит значения состояния для непосредственного управления управляющим выходом, этот бит сигнала состояния будет преобразован в управляющий выход того же значения.
Наконец, генерируется таблица переходов для FSM. Для этого используется вспомогательный класс ConstEval C++ (определен в kernel/consteval.h), который может быть использован для оценки частей конструкции. Класс ConstEval можно попросить вычислить заданный набор результирующих сигналов, используя набор назначений сигнал-значение. Ему также может быть передан список стоп-сигналов, которые прерывают алгоритм ConstEval, если для вычисления результирующих сигналов требуется значение стоп-сигнала.
Процедура fsm_extract использует класс ConstEval следующим образом для создания таблицы переходов. Для каждого состояния:
- Создает объект ConstEval для модуля, содержащего FSM
- Добавляет все управляющие входы в список стоп-сигналов
- Устанавливает сигнал состояния в текущее состояние
- Попробуйте оценить следующее состояние и управляющий выход
- Если шаг 4 не увенчался успехом:
- Рекурсивно перейдите к шагу 4, установив для нарушающего стоп-сигнала значение 0.
- Рекурсивно перейдите к шагу 4, установив для нарушающего стоп-сигнала значение 1.
- Если шаг 4 прошел успешно: Эмитировать переход
Наконец, создается ячейка $fsm со сгенерированной таблицей переходов и добавляется в модуль. Эта новая ячейка подключается к управляющим сигналам, а старые источники управляющих выходов отключаются.
3.1.3.3. Оптимизация FSM
Команда fsm_opt выполняет базовые оптимизации для ячеек $fsm (не включая перекодировку состояний). Выполняются следующие оптимизации (в этом порядке):
- Неиспользуемые управляющие выводы удаляются из ячейки $fsm. Атрибут \unused_bits (который обычно устанавливается передачей opt_clean) используется для определения неиспользуемых управляющих выводов.
- Входы управления, подключенные к одному и тому же источнику, объединяются.
- Если управляющий вход управляется управляющим выходом, управляющий вход удаляется, а таблица переходов изменяется таким образом, чтобы обеспечить ту же производительность без внешнего пути обратной связи.
- Записи в таблице переходов, которые дают одинаковый выход и отличаются только значением одного бита управляющего входа, объединяются, а отличающийся бит удаляется из списка чувствительности
- Постоянные входы удалены, а таблица переходов изменена, чтобы обеспечить неизменное поведение.
- Неиспользуемые входы удаляются.
3.1.3.4. Перекодирование FSM
Команда fsm_recode присваивает состояниям новую битовую схему. Обычно это также подразумевает изменение ширины сигнала состояния. На момент написания этой статьи(30.09.2024) поддерживается только одноточечное кодирование со всеми нулями для состояния сброса.
Передача fsm_recode также может записать текстовый файл с выполненными изменениями, который можно использовать при верификации проектов, синтезированных в Yosys с помощью Synopsys Formality.
3.1.4. Операции с памятью
3.1.4.1. Команда памяти
В RTL-нетлисте чтение и запись памяти — это отдельные ячейки. Это упрощает консолидацию количества портов для памяти. Команды memory преобразует память в имплементацию. По умолчанию это логика для дешифраторов адреса и регистров. Это макрокоманда, которая вызывает другие команды memory_* в установленном порядке:
opt_mem
opt_mem_priority
opt_mem_feedback
memory_bmux2rom
memory_dff
opt_clean
memory_share
opt_mem_widen
memory_memx (если был вызов с параметром -memx)
opt_clean
memory_collect
memory_bram -rules <bram_rules> (если был вызов с параметром -bram)
memory_map (если не было при вызове параметра -nomap)Небольшие заметки:
- memory_dff объединяет регистры в ячейки чтения и записи памяти.
- memory_collect собирает все ячейки чтения и записи для памяти и преобразует их в одну многопортовую ячейку памяти.
- memory_map берет многопортовую ячейку памяти и преобразует ее в логику и регистры дешифратора адреса.
Для получения дополнительной информации о memory, например, об отключении определенных подкоманд, см. раздел Память — перевод памяти в базовые ячейки.
3.1.4.2. Пример
docs/source/code_examples/synth_flow.
read_verilog memory_01.v
hierarchy -check -top test
proc;; memory; optЛистинг 3.11: memory_01.v
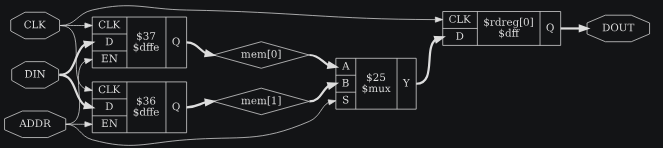
module test(input CLK, ADDR,
input [7:0] DIN,
output reg [7:0] DOUT);
reg [7:0] mem [0:1];
always @(posedge CLK) begin
mem[ADDR] <= DIN;
DOUT <= mem[ADDR];
end
endmodule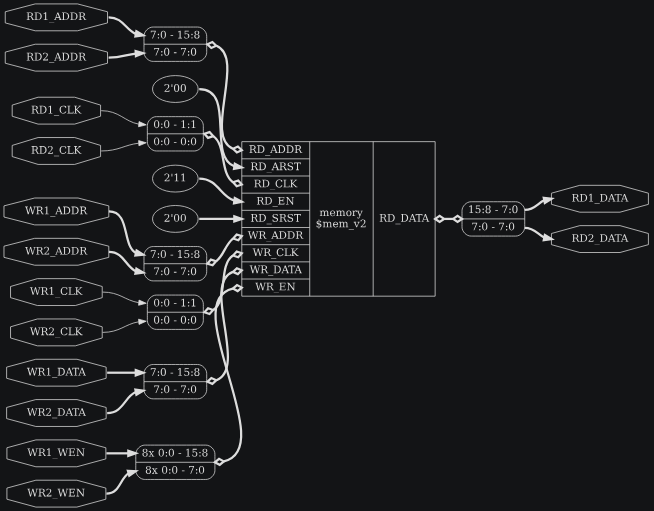
module test(
input WR1_CLK, WR2_CLK,
input WR1_WEN, WR2_WEN,
input [7:0] WR1_ADDR, WR2_ADDR,
input [7:0] WR1_DATA, WR2_DATA,
input RD1_CLK, RD2_CLK,
input [7:0] RD1_ADDR, RD2_ADDR,
output reg [7:0] RD1_DATA, RD2_DATA
);
reg [7:0] memory [0:255];
always @(posedge WR1_CLK)
if (WR1_WEN)
memory[WR1_ADDR] <= WR1_DATA;
always @(posedge WR2_CLK)
if (WR2_WEN)
memory[WR2_ADDR] <= WR2_DATA;
always @(posedge RD1_CLK)
RD1_DATA <= memory[RD1_ADDR];
always @(posedge RD2_CLK)
RD2_DATA <= memory[RD2_ADDR];
endmoduleread_verilog memory_02.v
hierarchy -check -top test
proc;; memory -nomap
opt -mux_undef -mux_bool3.1.4.3. Размещение памяти
Обычно предпочтительнее использовать для памяти ресурсы RAM, специфичные для конкретной архитектуры. Например:
memory -nomap
memory_libmap -lib my_memory_map.txt
techmap -map my_memory_map.v
memory_mapmemory_libmap пытается преобразовать ячейки памяти ($mem_v2 и т.д.) в аппаратно поддерживаемую память, используя предоставленную библиотеку (my_memory_map.txt в примере выше). При необходимости добавляется логика эмуляции для обеспечения функциональной эквивалентности до и после этого преобразования. techmap -map my_memory_map.v затем использует techmap для сопоставления с аппаратными примитивами. Все оставшиеся ячейки памяти, которые не могут быть преобразованы, затем подхватываются memory_map и отображаются на DFF и дешифраторы адресов.
Примечание: Более подробную информацию о доступных вариантах размещения и расходе ячеек каждого из них можно найти, включив вывод отладочных сообщений. Это можно сделать с помощью команды debug или используя флаг -g при вызове Yosys для глобального включения отладочных сообщений.
3.1.4.4. Поддерживаемые паттерны памяти
Обратите внимание, что в этот документ включены не все поддерживаемые модели. Особо следует отметить, что комбинации нескольких моделей, как правило, работают. Например, wbe можно использовать в сочетании с любой из моделей простой двухпортовой (SDP). В общем случае, если определение аппаратной памяти не поддерживает заданную конфигурацию, для обеспечения соответствия поведения моделированию будет добавлена дополнительная логика.
3.1.4.5. Примечания
3.1.4.5.1. Выбор типа памяти
Код вывода памяти автоматически выбирает примитив памяти устройства, основываясь на геометрии памяти и используемых функциях. В зависимости от цели, для выбора может быть доступно до четырех классов примитивов памяти:
- FF RAM (она же логика): аппаратный примитив не используется, память сводится к куче FF(триггеров) и мультиплексоров
- Может работать с произвольным количеством портов записи, если все порты записи находятся в одном тактовом домене
- Может работать с произвольным количеством и типом портов чтения
- LUT RAM (распределенная оперативная память): использует хранилище LUT в качестве оперативной памяти.
- Поддерживается на большинстве ПЛИС (за исключением ice40).
- Обычно имеет один порт синхронной записи, один или несколько портов асинхронного чтения
- Маленький
- Никогда не будет использоваться для ПЗУ (переход на обычные LUT всегда лучше).
- Блочная RAM: выделенные ячейки памяти
- Поддерживаются практически все ПЛИС
- Поддерживает только синхронное чтение
- Два порта с отдельными тактовыми сигналами
- Обычно поддерживается настоящий двухпортовый режим (за исключением ice40, который поддерживает только SDP).
- Обычно поддерживаются асимметричные памяти и возможность записи на каждый байт
- Размер в несколько килобайт
- Огромная RAM:
- Поддерживается только для нескольких устройств:
- Некоторые устройства Xilinx UltraScale (UltraRAM)
- Двухпортовая, оба с взаимоисключающими синхронными чтением и записью
- Однотактовая
- Исходные данные ячеек памяти должны быть равны 0
- Некоторые устройства ice40 (SPRAM)
- Однапортовая с взаимоисключающими синхронными чтениями и записями
- Не поддерживает исходные данные
- Nexus (большой объем оперативной памяти)
- Двухпортовая, оба с взаимоисключающими синхронными чтением и записью
- Однотактовая
- Некоторые устройства Xilinx UltraScale (UltraRAM)
- Не будет автоматически выбираться кодом вывода памяти, требуется явный выбор через атрибут ram_style
- Поддерживается только для нескольких устройств:
В целом, процесс автоматического выбора может работать примерно так:
- Если какой-либо порт чтения является асинхронным, можно использовать только LUT RAM (или FF RAM).
- Если имеется более одного порта для записи, можно использовать только блочную оперативную память, и это должна быть аппаратно поддерживаемый двухпортовый паттерн.
- … если только все порты записи не находятся в одном тактовом домене, в этом случае можно использовать и FF RAM, но это, как правило, не то, что вам нужно для чего-либо, кроме очень маленькой памяти.
- В противном случае будет использоваться либо FF RAM, LUT RAM, либо блочная RAM, в зависимости от объема памяти.
Этот процесс можно переопределить, приписав к памяти атрибут ram_style:
- (* ram_style = «logic» *) выбирает FF RAM
- (* ram_style = «distributed» *) выбирает LUT RAM
- (* ram_style = «block» *) выбирает блочную RAM
- (* ram_style = «huge» *) выбирает огромную RAM
Ошибкой будет, если это переопределение не может быть реализовано для данного устройства.
Для совместимости с другим программным обеспечением принимается также множество альтернативных написаний атрибута.
3.1.4.5.2. Исходные данные
Большинство FPGA-устройств поддерживают инициализацию всех видов памяти значениями, задаваемыми пользователем. Если явная инициализация не используется, исходные значение памяти не определено. Исходные данные могут быть предоставлены операторами initial, записывающими ячейки памяти с помощью системных задач $readmemh или $readmemb.
3.1.4.5.3. Порт записи с разрешающим байтом
- Разрешающий байт может быть использовано с любым поддерживаемым паттерном
- Чтобы гарантировать, что несколько записей будут объединены в один порт, они должны иметь несовпадающие диапазоны битов, один и тот же адрес и один и тот же тактовый сигнал.
- Любая размерность порта разрешающей записи будет принята (в точно до одного бита), но использование меньшей размерности, чем поддерживается системой устройства, скорее всего, будет неэффективным (например, использование 4-битных байтов на ECP5 приведет либо к заполнению байтов 5 фиктивными битами до 9-битных единиц, либо к разделению RAM на две блочные RAM).
reg [31 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable[0])
mem[write_addr][7:0] <= write_data[7:0];
if (write_enable[1])
mem[write_addr][15:8] <= write_data[15:8];
if (write_enable[2])
mem[write_addr][23:16] <= write_data[23:16];
if (write_enable[3])
mem[write_addr][31:24] <= write_data[31:24];
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.6. Паттерны простой двухпортовой памяти (SDP)
3.1.4.6.1. Асинхронное чтение SDP
- Придет в качестве результата LUT RAM на поддерживаемых объектах
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk)
if (write_enable)
mem[write_addr] <= write_data;
assign read_data = mem[read_addr];3.1.4.6.2. Синхронный SDP с пересечением тактовых доменов
- В зависимости от размера это будет Блочная или LUT RAM
- Нет гарантий определенного поведения в случае одновременного чтения и записи по одному и тому же адресу
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge write_clk) begin
if (write_enable)
mem[write_addr] <= write_data;
end
always @(posedge read_clk) begin
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.6.3. Приоритетное синхронное чтение SDP
- Части чтения и записи могут находиться в одном или разных процедурных блоках.
- В зависимости от размера это будет блок RAM или LUT RAM
- Если для обоих используется один и тот же тактовый генератор, yosys обеспечит работу в режиме чтения. Это может потребовать дополнительной схемы в некоторых целях для блочной оперативной памяти. Если в этом нет необходимости, используйте одну из приведенных ниже схем.
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.6.4. Синхронный SDP с неопределенным поведением с приоритетной операцией чтения
- Как и выше, но значение чтения не определено, если порты чтения и записи используют один и тот же адрес в одном цикле
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable) begin
read_data <= mem[read_addr];
if (write_enable && read_addr == write_addr)
// this if block
read_data <= 'x;
end
end- Или ниже, используя атрибут no_rw_check
(* no_rw_check *)
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.6.5. Синхронный SDP с приоритетной операцией записи
- В зависимости от размера это будет блок RAM или LUT RAM
- Может использоваться дополнительная схема для блочной RAM, если запись первой не поддерживается нативно. Для LUT RAM всегда будет использована дополнительная схема.
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable) begin
read_data <= mem[read_addr];
if (write_enable && read_addr == write_addr)
read_data <= write_data;
end
end3.1.4.6.6. Синхронный SDP с приоритетной операцией записи (альтернативный паттерн)
- Этот паттерн поддерживается для совместимости, но он гораздо менее гибкий, чем приведенный выше
reg [ADDR_WIDTH - 1 : 0] read_addr_reg;
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
read_addr_reg <= read_addr;
end
assign read_data = mem[read_addr_reg];3.1.4.7. Паттерны Однопортовой RAM
3.1.4.7.1. Однопортовая RAM с асинхронным чтением
- В результате на поддерживаемых объектах будет использоваться однопортовая LUT RAM
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk)
if (write_enable)
mem[addr] <= write_data;
assign read_data = mem[addr];3.1.4.7.2. Синхронная однопортовая RAM с взаимоисключающим чтением/записью
- В результате получится однопортовая блочная или LUT RAM в зависимости от размера
- Это правильный паттерн для вывода ice40 SPRAM (с ручным выбором ram_style)
- На объектах, не поддерживающих порты чтения/записи блочной RAM (например, ice40), вместо них будет использоваться блочная RAM SDP.
- Для блочной RAM будет использоваться режим «NO_CHANGE», если он доступен
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[addr] <= write_data;
else if (read_enable)
read_data <= mem[addr];
end3.1.4.7.3. Синхронная однопортовая RAM с приоритетной функцией чтения
- Однопортовая блочная RAM будет использоваться только в том случае, если поведение чтения первым поддерживается нативно. В противном случае будет использоваться SDP RAM с дополнительной схемой.
- Многие целевые устройства (Xilinx, ECP5, … ) могут поддерживать только однопортовую RAM (или TDP RAM), где сигнал write_enable подразумевает сигнал read_enable (т. е. запись без чтения невозможна). Код вывода памяти будет выполнять простой SAT-решатель для управляющих сигналов, чтобы определить, так ли это, и вставит схему эмуляции, если это не может быть легко доказано.
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[addr] <= write_data;
if (read_enable)
read_data <= mem[addr];
end3.1.4.7.4. Синхронная однопортовая RAM с приоритетной функцией записи
- При поддержке однопортовой блочной или LUT RAM
- Для блочных RAM потребуется дополнительная схема, если поведение записи первым не поддерживается
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[addr] <= write_data;
if (read_enable)
if (write_enable)
read_data <= write_data;
else
read_data <= mem[addr];
end3.1.4.7.5. Порт синхронного чтения с исходными значениями
- Начальные значения портов чтения можно комбинировать с любыми другими поддерживаемыми паттернами
- Если используется блочная RAM и начальные значения портов чтения не поддерживаются текущим устройством, будет вставлена небольшая схема эмуляции
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
reg [DATA_WIDTH - 1 : 0] read_data;
initial read_data = 'h1234;
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.8. Паттерны сброса регистров чтения
Сбросы можно комбинировать с любыми другими поддерживаемыми паттернами (за исключением того, что синхронный и асинхронный сбросы не могут использоваться в одном порту чтения). Если используется блочная RAM и выбранный сброс (синхронный или асинхронный) используется, но не поддерживается текущим устройством, в него будет вставлена небольшая схема эмуляции.
3.1.4.8.1. Синхронный сброс, где сброс приоритетнее разрешающего
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_reset)
read_data <= 'h1234;
else if (read_enable)
read_data <= mem[read_addr];
end3.1.4.8.2. Синхронный сброс, где разрешающий приоритетнее сброса
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable)
if (read_reset)
read_data <= 'h1234;
else
read_data <= mem[read_addr];
end3.1.4.8.3. Порт синхронного чтения с асинхронным сбросом
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
end
always @(posedge clk, posedge read_reset) begin
if (read_reset)
read_data <= 'h1234;
else if (read_enable)
read_data <= mem[read_addr];
end3.1.4.9. Асимметричные модели памяти
Построение асимметричной памяти (памяти с портами чтения/записи разной ширины):
- Объявите память с самой меньшей шириной порта.
- Разделите все широкие порты на несколько портов меньшей ширины
- Чтобы обеспечить правильное объединение широких портов:
- Для адреса используйте конкатенацию фактического адреса в старших битах и константы в младших битах
- Убедитесь, что фактический адрес идентичен для всех портов, входящих в широкий порт.
- Убедитесь, что тактовые идентичны
- Для портов чтения убедитесь, что сигналы разрешения/сброса идентичны (для портов записи сигнал разрешения может отличаться — это приведет к использованию функции разрешения байта).
Асимметричная память поддерживается на всех устройствах, но при отсутствии встроенной поддержки может потребоваться схема эмуляции. Обратите внимание, если память больше, чем базовый примитив блочной RAM, аппаратная поддержка асимметричной памяти, скорее всего, не будет использоваться, даже если она присутствует, так как она более дорогостоящая.
3.1.4.9.1. Широкий синхронный порт чтения
reg [7:0] mem [0:255];
wire [7:0] write_addr;
wire [5:0] read_addr;
wire [7:0] write_data;
reg [31:0] read_data;
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
if (read_enable) begin
read_data[7:0] <= mem[{read_addr, 2'b00}];
read_data[15:8] <= mem[{read_addr, 2'b01}];
read_data[23:16] <= mem[{read_addr, 2'b10}];
read_data[31:24] <= mem[{read_addr, 2'b11}];
end
end3.1.4.9.2. Широкий асинхронный порт чтения
- Примечание: единственной устройство, поддерживающей данный паттерн, является Xilinx UltraScale.
reg [7:0] mem [0:511];
wire [8:0] write_addr;
wire [5:0] read_addr;
wire [7:0] write_data;
wire [63:0] read_data;
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
end
assign read_data[7:0] = mem[{read_addr, 3'b000}];
assign read_data[15:8] = mem[{read_addr, 3'b001}];
assign read_data[23:16] = mem[{read_addr, 3'b010}];
assign read_data[31:24] = mem[{read_addr, 3'b011}];
assign read_data[39:32] = mem[{read_addr, 3'b100}];
assign read_data[47:40] = mem[{read_addr, 3'b101}];
assign read_data[55:48] = mem[{read_addr, 3'b110}];
assign read_data[63:56] = mem[{read_addr, 3'b111}];3.1.4.9.3. Широкий порт записи
reg [7:0] mem [0:255];
wire [5:0] write_addr;
wire [7:0] read_addr;
wire [31:0] write_data;
reg [7:0] read_data;
always @(posedge clk) begin
if (write_enable[0])
mem[{write_addr, 2'b00}] <= write_data[7:0];
if (write_enable[1])
mem[{write_addr, 2'b01}] <= write_data[15:8];
if (write_enable[2])
mem[{write_addr, 2'b10}] <= write_data[23:16];
if (write_enable[3])
mem[{write_addr, 2'b11}] <= write_data[31:24];
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.10. Двухпортовые модели (TDP)
- Множество различных вариантов настоящей двухпортовой памяти можно создать путем объединения двух паттернов однопортовой RAM на одной памяти
- При использовании памяти TDP у кода выводов памяти гораздо меньше пространства для маневра при создании требуемой семантики по сравнению с отдельными однопортовыми паттернами (которые при необходимости могут быть переведены на память SDP) — поддерживаемые паттерны сильно зависят от устройства
- В частности, если оба порта имеют одинаковый тактовый генератор, скорее всего, необходимо вручную выбрать режим «неопределенной коллизии», чтобы включить функцию TDP memory inference
- Приведенные ниже примеры не являются исчерпывающими — возможны и другие комбинации типов портов.
- Примечание: если два порта записи находятся в одном процедурном блоке, это определяет отношение приоритета между ними (если оба порта активны в один и тот же такт, побеждает более поздний). Практически на всех объектах это приведет к появлению дополнительной схемы для обеспечения семантики приоритета. Если это не то, что вам нужно, поместите их в отдельные процедурные блоки.
- Приоритет не поддерживается при использовании verific frontend, и любая семантика приоритета игнорируется.
3.1.4.10.1. TDP с разными тактовыми сигналами с чтение/запись
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk_a) begin
if (write_enable_a)
mem[addr_a] <= write_data_a;
else if (read_enable_a)
read_data_a <= mem[addr_a];
end
always @(posedge clk_b) begin
if (write_enable_b)
mem[addr_b] <= write_data_b;
else if (read_enable_b)
read_data_b <= mem[addr_b];
end3.1.4.10.2. TDP с одним тактовым сигналом с приоритетной операцией чтением
- Это требует аппаратного межпортового чтения, и будет работать только на некоторых объектах (Xilinx, Nexus).
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable_a)
mem[addr_a] <= write_data_a;
if (read_enable_a)
read_data_a <= mem[addr_a];
end
always @(posedge clk) begin
if (write_enable_b)
mem[addr_b] <= write_data_b;
if (read_enable_b)
read_data_b <= mem[addr_b];
end3.1.4.10.3. TDP с несколькими портами чтения
- Комбинация одного порта записи с произвольным количеством портов чтения поддерживается на всех объектах — если доступен примитив с несколькими портами чтения (например, Xilinx RAM64M), он будет использован соответствующим образом. В противном случае память будет автоматически разделена на несколько примитивов.
reg [31:0] mem [0:31];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] <= write_data;
end
assign read_data_a = mem[read_addr_a];
assign read_data_b = mem[read_addr_b];
assign read_data_c = mem[read_addr_c];3.1.4.11. Паттерны поддерживаются только в Verific
Следующие паттерны поддерживаются только при считывании конструкции с помощью Verific frontend.
3.1.4.12. Синхронный SDP с приоритетной операцией записи с помощью блокирующих назначения(присвоения)
Используйте sdp_wf для совместимости с фронтендом Yosys Verilog.
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @(posedge clk) begin
if (write_enable)
mem[write_addr] = write_data;
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.13. Асимметричная память за счет выбора частей
Для совместимости с Frontend Yosys Verilog создайте широкие порты из нешироких портов (см. wide_sr).
reg [31:0] mem [2**ADDR_WIDTH - 1 : 0];
wire [1:0] byte_lane;
wire [7:0] write_data;
always @(posedge clk) begin
if (write_enable)
mem[write_addr][byte_lane * 8 +: 8] <= write_data;
if (read_enable)
read_data <= mem[read_addr];
end3.1.4.14. Нежелательные паттерны
3.1.4.14.1. Асинхронная запись
- Не поддерживается в современных ПЛИС
- В любом случае, в коде yosys это не поддерживается
reg [DATA_WIDTH - 1 : 0] mem [2**ADDR_WIDTH - 1 : 0];
always @* begin
if (write_enable)
mem[write_addr] = write_data;
end
assign read_data = mem[read_addr];3.1.5. Команды оптимизации
Yosys использует ряд оптимизаций для получения более качественных и чистых результатов. В этой главе описываются эти оптимизации.
3.1.5.1. Макрокоманда opt
В Yosys команда opt выполняет ряд простых оптимизаций. К ним относится удаление неиспользуемых сигналов и ячеек и упрощение константных выражений. Рекомендуется запускать эту команду после каждого основного шага в сценарии синтеза. Эта макрокоманда вызывает следующие команды opt_*:
opt_expr
opt_merge -nomux
do
opt_muxtree
opt_reduce
opt_merge
opt_share (-full only)
opt_dff (except when called with -noff)
opt_clean
opt_expr
while <changed design>3.1.5.2. Упрощение и простая перезапись константных выражений — opt_expr
Этот команда выполняет упрощение константных выражений на внутренних комбинационных ячейках, описанных в библиотеке внутренних ячеек(глава 4.2.4.). Это означает, что ячейка со всеми постоянными входами заменяется постоянным значением, управляемым этой ячейкой. В некоторых случаях эта команда может также оптимизировать ячейки с некоторыми постоянными входами.
| A-Input | B-Input | Replacement |
|---|---|---|
| any | 0 | 0 |
| 0 | any | 0 |
| 1 | 1 | 1 |
| X/Z | X/Z | X |
| 1 | X/Z | X |
| X/Z | 1 | X |
| any | X/Z | 0 |
| X/Z | any | 0 |
| a | 1 | a |
| 1 | b | b |
В табл. 3.1 приведены правила замены, используемые для оптимизации вентилей $_AND_. Первые три правила реализуют очевидные правила упрощения константных выражений. Обратите внимание, что «any» может включать динамические значения, вычисляемые другими частями схемы. Следующие три строки распространяют состояния undef (X). Это единственные три случая, когда разрешено распространять undef в соответствии с п. 5.1.10 стандарта IEEE 1364-2005.
Следующие две строки принимают значение 0 для состояний undef. Эти два правила используются только в том случае, если в текущем модуле невозможны другие подстановки. Если другие подстановки возможны, они выполняются первыми, в надежде, что ‘any’ изменится на значение undef или 1 и, следовательно, выход может быть установлен в undef.
Последние две строки просто заменяют вентили $_AND_ с одним входом constant-1 на буфер.
Кроме этого базового упрощения, передача opt_expr может заменить ячейки $eq и $ne шириной в 1 бит буферами или без вентилей, если один из входов является постоянным. Проверки равенства также могут быть уменьшены в размере, если есть лишние биты в аргументах (т.е. битов, которые постоянны на обоих входах). Это может, например, привести к тому, что константа шириной 32 бита, например 255, будет уменьшена до 8-битного значения 8’11111111, если сравниваемый сигнал только 8-битный, как в модуле addr_gen после opt_expr; clean в Synthesis starter.
Передача opt_expr очень консервативна в отношении оптимизации ячеек $mux, так как эти ячейки часто используются для моделирования деревьев решений, и разрушение этих деревьев может помешать другим оптимизациям.
Листинг 3.15: пример verilog для демонстрации opt_expr
module uut(
input a,
output y, z
);
assign y = a == a;
assign z = a != a;
endmodule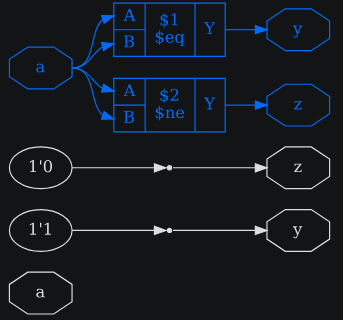
3.1.5.3. Слияние одинаковых ячеек — opt_merge
Этот команда выполняет тривиальное разделение ресурсов. Это означает, что данный команда определяет ячейки с одинаковыми входами и заменяет их одним экземпляром ячейки.
Опция -nomux может быть использована для отключения разделения ресурсов для ячеек мультиплексора ($mux и $pmux). Это может быть полезно, так как предотвращает объединение деревьев мультиплексоров, что может помешать opt_muxtree определить возможные оптимизации.
Листинг 3.16: пример verilog для демонстрации opt_merge
module uut(
input [3:0] a, b,
output [3:0] y, z
);
assign y = a + b;
assign z = b + a;
endmodule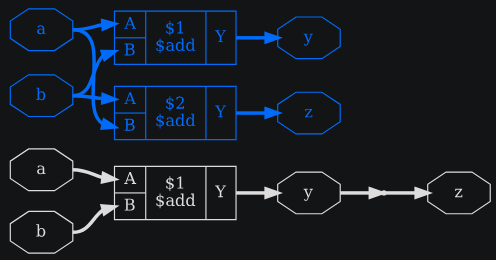
3.1.5.4. Удаление не активных ветвей из дерева мультиплексоров — opt_muxtree
Этот команда оптимизирует деревья ячеек мультиплексора, анализируя входы выбора. Рассмотрим следующий простой пример:
Листинг 3.17: пример verilog для демонстрации opt_muxtree
module uut(
input a, b, c, d,
output y
);
assign y = a ? (a ? b : c) : d;
endmodule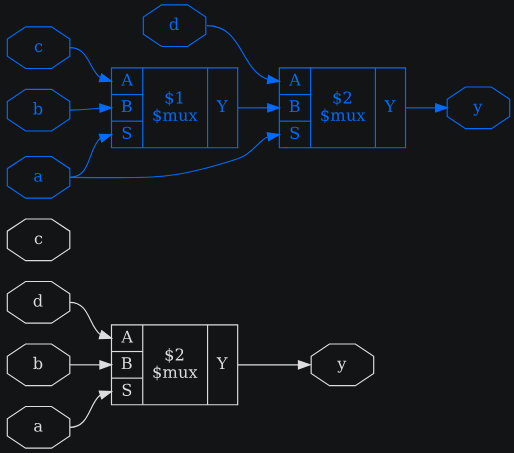
Выход никогда не может быть c, так как для этого нужно, чтобы a было 1 для внешнего мультиплексора и 0 для внутреннего мультиплексора. Процедура opt_muxtree обнаруживает это противоречие и заменяет внутренний мультиплексор на a константой 1.
3.1.5.5. Упрощение больших MUX и AND/OR вентилей — opt_reduce
Это простая операция оптимизации, которая выявляет и объединяет одинаковые входные биты в ячейках $reduce_and и $reduce_or. Он также сортирует входные биты, чтобы облегчить определение совместно используемых ячеек $reduce_and и $reduce_or в других командах.
Этот команда также выявляет и объединяет идентичные входы в ячейки мультиплексора. В этом случае новый общий бит выбора управляется с помощью ячейки $reduce_or, которая объединяет исходные биты выбора.
Наконец, эта команда объединяет деревья ячеек $reduce_and и деревья ячеек $reduce_or в одну большую ячейку $reduce_and или $reduce_or.
Эти три простые оптимизации выполняются в цикле до тех пор, пока не будет получен стабильный результат.
3.1.5.6. Объединение взаимоисключающих ячеек с общими входами — opt_share
Этот команда определяет взаимоисключающие клетки одного типа, которые:
- совместное использование входной сигнал
- управляют одной и той же ячейкой мультиплексирования $mux, $_MUX_ или $pmux,
что позволяет объединить ячейки и перевести мультиплексор с мультиплексирования своего выхода на мультиплексирование не совместно использующих входной сигнал.
Листинг 3.18: пример verilog для демонстрации opt_share
module uut(
input [15:0] a, b,
input sel,
output [15:0] res,
);
assign res = {sel ? a + b : a - b};
endmodule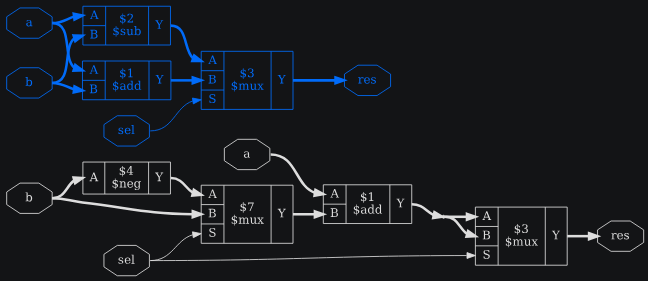
При выполнении opt в полном объеме исходный $mux (обозначенный $3) оптимизируется opt_expr.
3.1.5.7. Выполнение оптимизаций DFF — opt_dff
Этот команда определяет однобитные триггеры d-типа $(_DFF_, $dff и $adff) с постоянным входом данных и заменяет их постоянным источником. Он также может объединить мультиплексоры разрешения тактовых импульсов и синхронного сброса, удалив неиспользуемые управляющие входы.
Если вызвать с параметров -nodffe и -nosdff, эта команда используется для подготовки дизайна к работе с FSM.
3.1.5.8. Удаление неиспользуемых ячеек и проводов — opt_clean
Эта команда определяет неиспользуемые сигналы и ячейки и удаляет их из проекта. Он также создает атрибут \ unused_bits для проводов с неиспользуемыми битами. Этот атрибут может быть использован для отладки или другими командами оптимизации.
3.1.5.9. Когда использовать opt или clean
Обычно команду opt вызывают после каждой обычной команды в сценарии синтеза. Но это увеличивает время синтеза, поэтому выгодно вызывать opt только в тех случаях, когда можно добиться улучшения.
Рекомендуется вызывать opt перед такими дорогостоящими командами, как sat или freduce, поскольку возможный выигрыш в этих случаях гораздо выше, чем возможный проигрыш.
Команда clean, которая является псевдонимом opt_clean с меньшей детализацией сообщения отладки, с другой стороны, очень быстрая, и многие команды оставляют беспорядок (болтающиеся сигнальные провода и т. д.). Например, большинство команд не удаляют никаких проводов или ячеек. Они просто меняют соединения и зависят от последующего вызова clean, чтобы избавиться от теперь уже неиспользуемых объектов. Поэтому в каждом скрипте синтеза не помешает иногда использовать ;;, который сам по себе является псевдонимом для clean, например
hierarchy; proc; opt; memory; opt_expr;; fsm;;3.1.5.10. Другие оптимизации
- wreduce — по возможности уменьшить размер слова
- peepopt — коллекция peephole-оптимизаторов
- share — совместное использование ресурсов на основе sat
- abc и abc9 , см. также: Набор инструментов ABC.
3.1.6. Технологическое размещение
В предыдущих главах описывалось, как HDL-код преобразуется в RTL-схему. Нетлист RTL по-прежнему основан на абстрактных типах coarse-grain ячеек, таких как сумматоры произвольной ширины и даже умножители. В этой главе рассказывается о том, как RTL-схема преобразуется в функционально эквивалентную схему с использованием типов ячеек, доступных в архитектуре устройства.
Технологическое размещение часто выполняется в два этапа. На первом этапе RTL ячейки размещаются с помощью внутренней библиотеки однобитных ячеек (см. раздел Gates). На втором этапе этот нетлист внутренних типов вентилей преобразуется в нетлист вентилей из библиотеки технологии устройства.
Если в архитектуре устройства предусмотрены coarse-grain ячейки (например, блочные память или АЛУ), их необходимо размещать непосредственно в нетлист RTL, поскольку информация о coarse-grain структуре проекта теряется при ее размещении на типы вентилей с битовой шириной.
3.1.6.1. Замена ячеек
Простейшей формой технологического размещения является замена ячеек, выполняемая командой techmap. Эта команда, когда ей предоставляется файл Verilog, реализующий типы ячеек RTL с помощью более простых ячеек, просто заменяет ячейки RTL на предоставленную реализацию.
Если файл не предоставлен, techmap использует встроенный файл, который сопоставляет типы ячеек Yosys RTL с внутренней библиотекой вентилей, используемой Yosys. Любопытный читатель может найти этот файл в файле astechlibs/common/techmap.v в дереве исходниках Yosys.
В techmap были добавлены дополнительные возможности для условного отображения ячеек. Это может быть полезно, например, если архитектура устройства поддерживает аппаратное обеспечение множителей для одних битов, но не для других.
В обычном потоке синтеза сначала используется передача techmap для прямого сопоставления некоторых ячеек RTL с ячейками coarse-grain, предоставляемыми архитектурой устройства (если таковые имеются), а затем используется techmap со встроенным файлом по умолчанию для сопоставления оставшихся ячеек RTL с логикой вентилей.
3.1.6.2. Замена подсхем
Иногда архитектура устройства предоставляет ячейки, более мощные, чем RTL-ячейки, используемые Yosys. Например, ячейка в архитектуре устройства, которая может вычислять абсолютную разность двух чисел, не соответствует ни одному типу RTL-ячеек, а только их комбинациям.
Для таких случаев Yosys предоставляет функцию извлечения, которая может сопоставить заданный набор модулей с конструкцией и определить части конструкции, которые идентичны (т.е. изоморфные подсхемы) любому из заданных модулей. Эти совпадающие подсхемы затем заменяются экземплярами заданных модулей.
В процессе извлечения также можно найти основные вариации заданных модулей, например, заменить местами входы в коммутативных типах ячеек.
Кроме того, команда извлечения имеет ограниченную поддержку поиска частых подсхем, т. е. процесса поиска повторяющихся подсхем в конструкции. Это имеет несколько применений, включая проектирование новых coarse-grain архитектур.
Тяжелая алгоритмическая работа, выполняемая при команде извлечения (решение проблемы изоморфной подсхемы и поиск частых подсхем), выполняется с помощью библиотеки SubCircuit, которая также может использоваться отдельно, без Yosys (см. SubCircuit).
3.1.6.3. Технологическое размещение на уровне вентилей
На уровне вентилей архитектура устройства обычно описывается «файлом Liberty». Формат файла Liberty — это промышленный стандарт, который можно использовать для описания поведения и других свойств стандартных библиотечных ячеек.
Сопоставление проекта, использующего внутреннюю библиотеку вентилей Yosys (например, в результате сопоставления с этим представлением с помощью передачи techmap), выполняется в два этапа.
Сначала регистровые ячейки должны быть размещены на регистры, доступные в архитектурах устройства. Архитектура устройства может не предоставлять все варианты триггеров D-типа с положительным и отрицательным фронтом тактового импульса, высокоактивным и низкоактивным асинхронными установкой и/или сбросом и т. д. Поэтому процесс размещения регистров может добавить в проект дополнительные инверторы, и поэтому важно сначала отобразить ячейки регистров.
Сопоставление регистровых ячеек может быть выполнено с помощью команды dfflibmap. Эта команда принимает в качестве аргумента файл Liberty (с помощью опции -liberty) и использует только регистровые ячейки из файла Liberty.
Во-вторых, комбинационная логика должна быть сопоставлена с архитектурой устройства. Это делается с помощью внешней программы ABC через команду abc с использованием параметра -liberty. Обратите внимание, что в этом случае используются только комбинаторные ячейки из библиотеки ячеек.
Иногда файлы Liberty содержат коммерческие секреты (например, конфиденциальную информацию о времени), которыми нельзя свободно делиться. Это усложняет такие процессы, как сообщение об ошибках в соответствующих инструментах. Когда информация в файле Liberty, используемом Yosys и ABC, не являются частью конфиденциальной информации, то для удаления конфиденциальной информации из файла Liberty можно использовать дополнительный инструмент yosys-filterlib.
3.1.7. Команда extract
- Как и команда techmap, команда extract вызывается с файлом размещения. Он сравнивает схемы внутри модулей файлом размещения с конструкцией и ищет в конструкцию подсхемы, которые соответствуют любому из модулей в файле размещения.
- Если совпадение найдено, команда extract заменит совпадающую подсхему экземпляром модуля из файла размещения.
- В некотором смысле команда extract — это обратная сторона команды techmap.
Примеры кода можно найти в docs/source/code_examples/macc.
read_verilog macc_simple_test.v
hierarchy -check -top test;;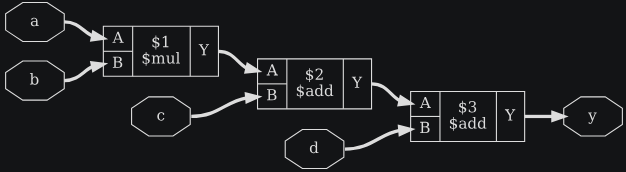
extract -constports -map macc_simple_xmap.v;;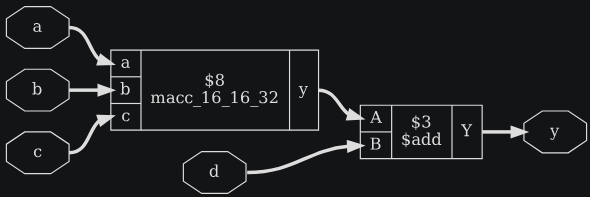
module test(a, b, c, d, y);
input [15:0] a, b;
input [31:0] c, d;
output [31:0] y;
assign y = a * b + c + d;
endmodulemodule macc_16_16_32(a, b, c, y);
input [15:0] a, b;
input [31:0] c;
output [31:0] y;
assign y = a*b + c;
endmoduleЛистинг 3.21: macc_simple_test_01.v
module test(a, b, c, d, x, y);
input [15:0] a, b, c, d;
input [31:0] x;
output [31:0] y;
assign y = a*b + c*d + x;
endmodule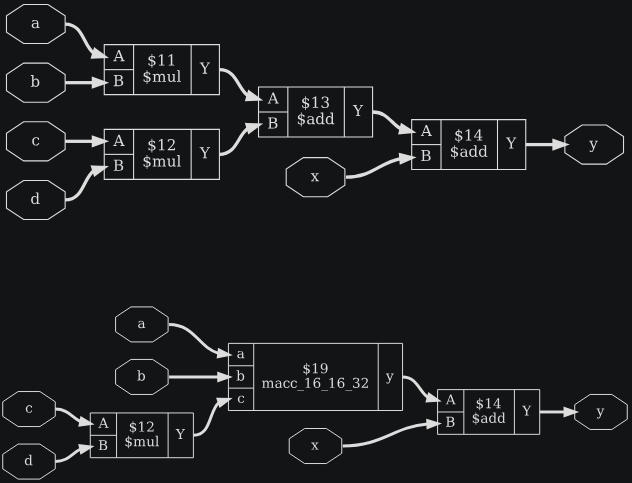
module test(a, b, c, d, x, y);
input [15:0] a, b, c, d;
input [31:0] x;
output [31:0] y;
assign y = a*b + (c*d + x);
endmodule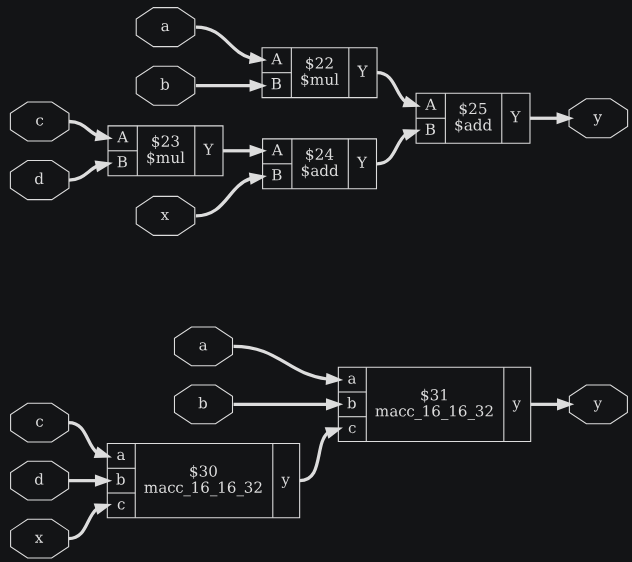
3.1.7.1. Метод «wrap-extract-unwrap»
Часто coarse-grain элемент имеет постоянную битовую ширину, но может использоваться для реализации операций с меньшей битовой шириной. Например, 18×25-битный умножитель может быть использован для реализации 16×20-битного умножения.
Способом размещения таких элементов при coarse-grain синтезе является метод wrap-extract-unwrap:
- wrap
Определите целевые ячейки в схеме и оберните их в ячейку с постоянной большей шириной портов с помощью techmap. Обертки используют те же параметры, что и исходная ячейка, поэтому информация об исходной ширине портов сохраняется. Затем с помощью команды connwrappers соедините расширенные по битам входы и выходы ячеек-оберток.
- extract
Теперь все операции кодируются с использованием той же ширины битов, что и в coarse-grain элементе. Команда extract может быть использована для замены схем на ячейки архитектуры устройства.
- unwrap
Оставшуюся ячейку-обертку можно развернуть с помощью techmap.
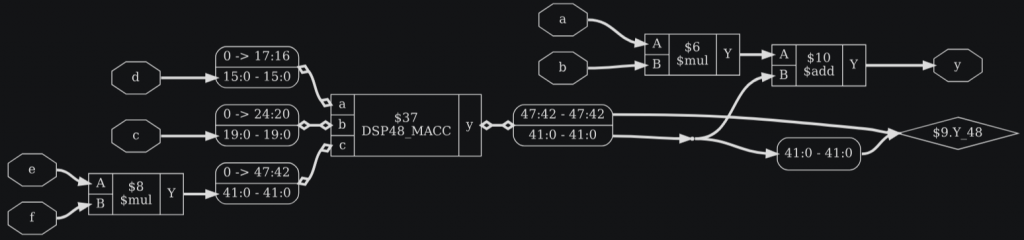
3.1.7.2. Пример: DSP48_MACC
В этом разделе приведен пример, показывающий, как разместить MACC-операции произвольного размера на MACC-ячейки с 18×25-битным умножителем и 48-битным сумматором (например, ячейки Xilinx DSP48).
Предварительная обработка: macc_xilinx_swap_map.v
Убедитесь, что A — меньший из портов на всех множителях.
(* techmap_celltype = "$mul" *)
module mul_swap_ports (A, B, Y);
parameter A_SIGNED = 0;
parameter B_SIGNED = 0;
parameter A_WIDTH = 1;
parameter B_WIDTH = 1;
parameter Y_WIDTH = 1;
input [A_WIDTH-1:0] A;
input [B_WIDTH-1:0] B;
output [Y_WIDTH-1:0] Y;
wire _TECHMAP_FAIL_ = A_WIDTH <= B_WIDTH;
$mul #(
.A_SIGNED(B_SIGNED),
.B_SIGNED(A_SIGNED),
.A_WIDTH(B_WIDTH),
.B_WIDTH(A_WIDTH),
.Y_WIDTH(Y_WIDTH)
) _TECHMAP_REPLACE_ (
.A(B),
.B(A),
.Y(Y)
);
endmoduleОбертывание множителей: macc_xilinx_wrap_map.v
(* techmap_celltype = "$mul" *)
module mul_wrap (A, B, Y);
parameter A_SIGNED = 0;
parameter B_SIGNED = 0;
parameter A_WIDTH = 1;
parameter B_WIDTH = 1;
parameter Y_WIDTH = 1;
input [A_WIDTH-1:0] A;
input [B_WIDTH-1:0] B;
output [Y_WIDTH-1:0] Y;
wire [17:0] A_18 = A;
wire [24:0] B_25 = B;
wire [47:0] Y_48;
assign Y = Y_48;
wire [1023:0] _TECHMAP_DO_ = "proc; clean";
reg _TECHMAP_FAIL_;
initial begin
_TECHMAP_FAIL_ <= 0;
if (A_SIGNED || B_SIGNED)
_TECHMAP_FAIL_ <= 1;
if (A_WIDTH < 4 || B_WIDTH < 4)
_TECHMAP_FAIL_ <= 1;
if (A_WIDTH > 18 || B_WIDTH > 25)
_TECHMAP_FAIL_ <= 1;
if (A_WIDTH*B_WIDTH < 100)
_TECHMAP_FAIL_ <= 1;
end
$__mul_wrapper #(
.A_SIGNED(A_SIGNED),
.B_SIGNED(B_SIGNED),
.A_WIDTH(A_WIDTH),
.B_WIDTH(B_WIDTH),
.Y_WIDTH(Y_WIDTH)
) _TECHMAP_REPLACE_ (
.A(A_18),
.B(B_25),
.Y(Y_48)
);
endmoduleОбертывание сумматоров: macc_xilinx_wrap_map.v
(* techmap_celltype = "$add" *)
module add_wrap (A, B, Y);
parameter A_SIGNED = 0;
parameter B_SIGNED = 0;
parameter A_WIDTH = 1;
parameter B_WIDTH = 1;
parameter Y_WIDTH = 1;
input [A_WIDTH-1:0] A;
input [B_WIDTH-1:0] B;
output [Y_WIDTH-1:0] Y;
wire [47:0] A_48 = A;
wire [47:0] B_48 = B;
wire [47:0] Y_48;
assign Y = Y_48;
wire [1023:0] _TECHMAP_DO_ = "proc; clean";
reg _TECHMAP_FAIL_;
initial begin
_TECHMAP_FAIL_ <= 0;
if (A_SIGNED || B_SIGNED)
_TECHMAP_FAIL_ <= 1;
if (A_WIDTH < 10 && B_WIDTH < 10)
_TECHMAP_FAIL_ <= 1;
end
$__add_wrapper #(
.A_SIGNED(A_SIGNED),
.B_SIGNED(B_SIGNED),
.A_WIDTH(A_WIDTH),
.B_WIDTH(B_WIDTH),
.Y_WIDTH(Y_WIDTH)
) _TECHMAP_REPLACE_ (
.A(A_48),
.B(B_48),
.Y(Y_48)
);
endmoduleИзвлечение: macc_xilinx_xmap.v
module DSP48_MACC (a, b, c, y);
input [17:0] a;
input [24:0] b;
input [47:0] c;
output [47:0] y;
assign y = a*b + c;
endmoduleПросто используйте те же команды обертывания на этом модуле, что и на дизайне, чтобы создать шаблон для команды extract.
Разворачивание множителей: macc_xilinx_unwrap_map.v
module $__mul_wrapper (A, B, Y);
parameter A_SIGNED = 0;
parameter B_SIGNED = 0;
parameter A_WIDTH = 1;
parameter B_WIDTH = 1;
parameter Y_WIDTH = 1;
input [17:0] A;
input [24:0] B;
output [47:0] Y;
wire [A_WIDTH-1:0] A_ORIG = A;
wire [B_WIDTH-1:0] B_ORIG = B;
wire [Y_WIDTH-1:0] Y_ORIG;
assign Y = Y_ORIG;
$mul #(
.A_SIGNED(A_SIGNED),
.B_SIGNED(B_SIGNED),
.A_WIDTH(A_WIDTH),
.B_WIDTH(B_WIDTH),
.Y_WIDTH(Y_WIDTH)
) _TECHMAP_REPLACE_ (
.A(A_ORIG),
.B(B_ORIG),
.Y(Y_ORIG)
);
endmoduleРазворачивание сумматоров: macc_xilinx_unwrap_map.v
module $__add_wrapper (A, B, Y);
parameter A_SIGNED = 0;
parameter B_SIGNED = 0;
parameter A_WIDTH = 1;
parameter B_WIDTH = 1;
parameter Y_WIDTH = 1;
input [47:0] A;
input [47:0] B;
output [47:0] Y;
wire [A_WIDTH-1:0] A_ORIG = A;
wire [B_WIDTH-1:0] B_ORIG = B;
wire [Y_WIDTH-1:0] Y_ORIG;
assign Y = Y_ORIG;
$add #(
.A_SIGNED(A_SIGNED),
.B_SIGNED(B_SIGNED),
.A_WIDTH(A_WIDTH),
.B_WIDTH(B_WIDTH),
.Y_WIDTH(Y_WIDTH)
) _TECHMAP_REPLACE_ (
.A(A_ORIG),
.B(B_ORIG),
.Y(Y_ORIG)
);
endmoduleЛистинг 3.29: test1 из файла macc_xilinx_test.v
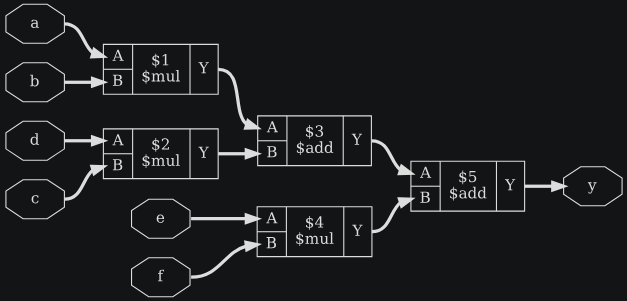
module test1(a, b, c, d, e, f, y);
input [19:0] a, b, c;
input [15:0] d, e, f;
output [41:0] y;
assign y = a*b + c*d + e*f;
endmodule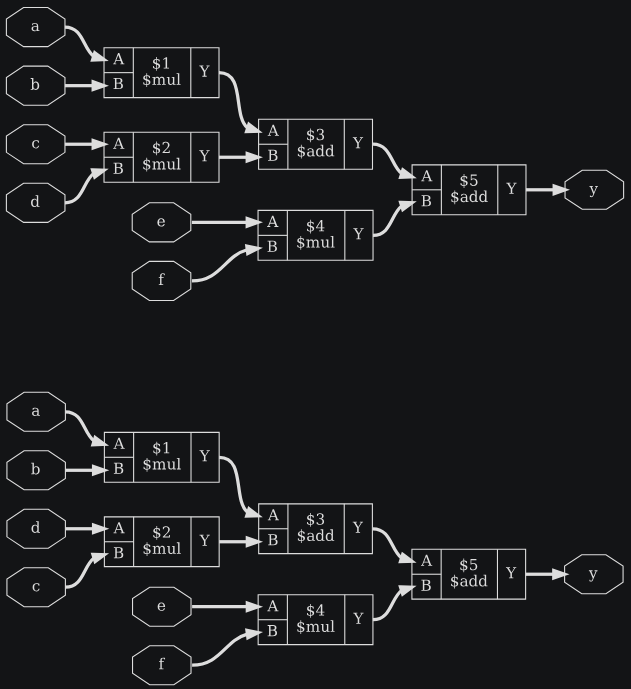
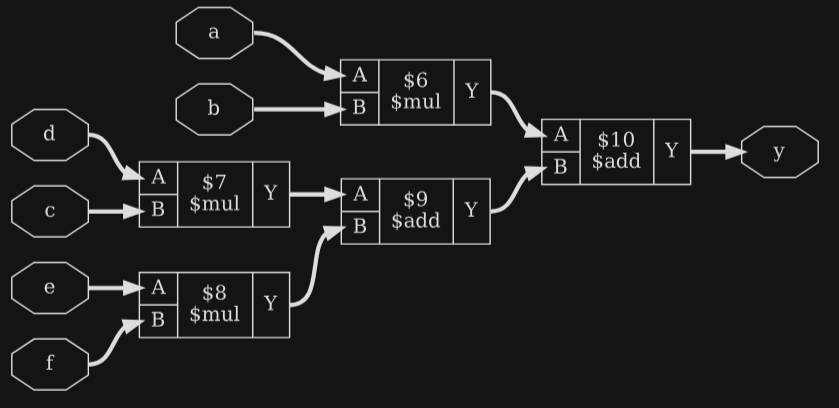
module test2(a, b, c, d, e, f, y);
input [19:0] a, b, c;
input [15:0] d, e, f;
output [41:0] y;
assign y = a*b + (c*d + e*f);
endmodule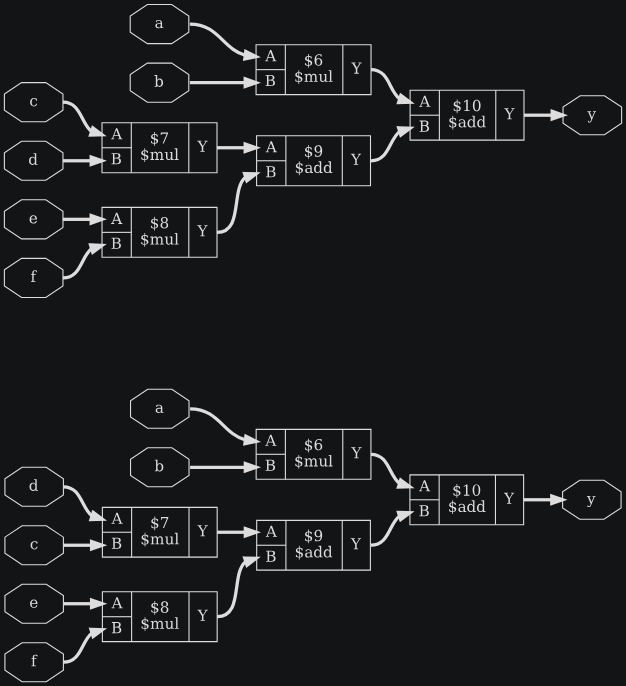
techmap -map macc_xilinx_wrap_map.v
connwrappers -unsigned $__mul_wrapper Y Y_WIDTH \
-unsigned $__add_wrapper Y Y_WIDTH;;
techmap -map macc_xilinx_wrap_map.v
connwrappers -unsigned $__mul_wrapper Y Y_WIDTH \
-unsigned $__add_wrapper Y Y_WIDTH;;

design -push
read_verilog macc_xilinx_xmap.v
techmap -map macc_xilinx_swap_map.v
techmap -map macc_xilinx_wrap_map.v;;
design -save __macc_xilinx_xmap
design -pop
extract -constports -ignore_parameters \
-map %__macc_xilinx_xmap \
-swap $__add_wrapper A,B ;;

design -push
read_verilog macc_xilinx_xmap.v
techmap -map macc_xilinx_swap_map.v
techmap -map macc_xilinx_wrap_map.v;;
design -save __macc_xilinx_xmap
design -pop
extract -constports -ignore_parameters \
-map %__macc_xilinx_xmap \
-swap $__add_wrapper A,B ;;